

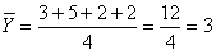 |
Estos cálculos se pueden simbolizar:
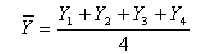 |
Donde Y1 es el valor de la variable en la primera observación, Y2 es el valor de la segunda observación y así sucesivamente. En general, con “n” observaciones, Yi representa el valor de la i-ésima observación. En este caso el promedio está dado por
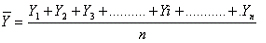 |
De aquí se desprende la fórmula definitiva del promedio:
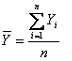 |
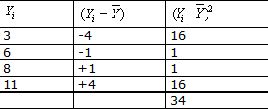
Desviaciones: Se define como la desviación de un dato a la diferencia entre el valor del dato y la media:
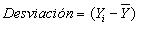 |
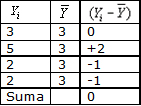
Ejemplo de desviaciones:
 |
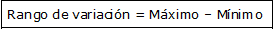 |
La mejor medida de dispersión, y la más generalizada es la varianza, o su raíz cuadrada, la desviación estándar. La varianza se representa con el símbolo σ² (sigma cuadrado) para el universo o población y con el símbolo s2 (s cuadrado), cuando se trata de la muestra. La desviación estándar, que es la raíz cuadrada de la varianza, se representa por σ (sigma) cuando pertenece al universo o población y por “s”, cuando pertenece a la muestra. σ² y σ son parámetros, constantes para una población particular; s2 y s son estadígrafos, valores que cambian de muestra en muestra dentro de una misma población. La varianza se expresa en unidades de variable al cuadrado y la desviación estándar simplemente en unidades de variable.
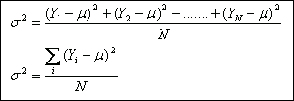 |
Donde Ȳ es el promedio de la muestra.
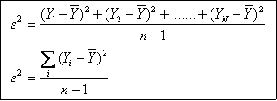 |
 |
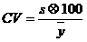 |
Es de particular utilidad para comparar la dispersión entre variables con distintas unidades de medida. Esto porque el coeficiente de variación, a diferencia de la desviación estándar, es independiente de la unidad de medida de la variable de estudio.
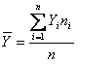 |
Donde ni representa cada una de las frecuencias correspondientes a los diferentes valores de Yi.
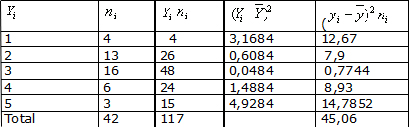
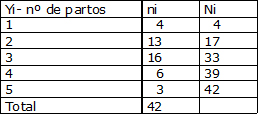
Consideremos como ejemplo una distribución de frecuencia de madres que asisten a un programa de lactancia materna, clasificadas según el número de partos. Por tratarse de una variable en escala discreta, las clases o categorías asumen sólo ciertos valores: 1, 2, 3, 4, 5.
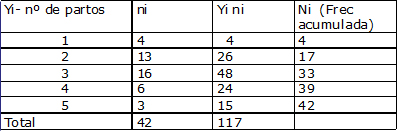 |
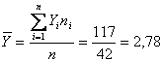 |
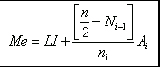 |
Donde:
 |
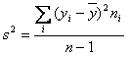 |
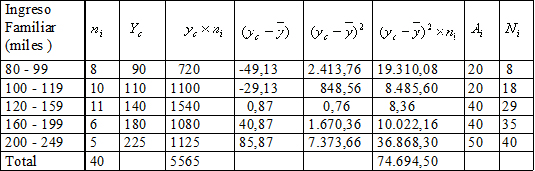
Con los datos del ejemplo y recordando que el promedio (Y) resultó ser 2,78 partos por madre,
 |
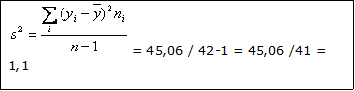 |
Cuando los datos están agrupados en intervalos de clase, se trabaja con la marca de clase (Yc), de tal modo que la fórmula queda:
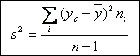 |
 |
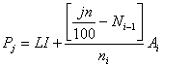 |
 |
1. El ingreso mensual promedio será:
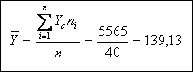 |
2. La mediana será:
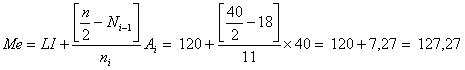 |
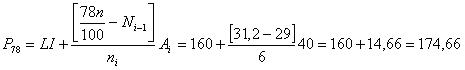 |
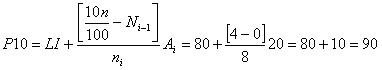 |
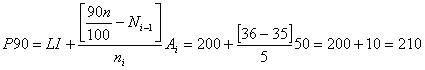 |
A base de los valores de los percentiles 10 y 90 se pueden hacer tres afirmaciones:
5. - La varianza será:
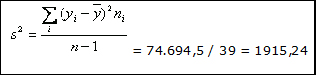 |
Usamos este tipo de tablas cuando tenemos variables cualitativas, o variables cuantitativas con pocos valores.
Esta tabla está compuesta por las siguientes columnas:
Ejemplo 1:
Se le pidió a un grupo de personas que indiquen su color favorito, y se obtuvo los siguientes resultados:
| negro | azul | amarillo | rojo | azul |
| azul | rojo | negro | amarillo | rojo |
| rojo | amarillo | amarillo | azul | rojo |
| negro | azul | rojo | negro | amarillo |
Con los resultados obtenidos, elaborar una tabla de frecuencias.
Solución:
En la primera columna, colocamos los valores de nuestra variable, en la segunda la frecuencia absoluta, luego la frecuencia acumulada, seguida por la frecuencia relativa, y finalmente la frecuencia relativa acumulada. Por ser el primer problema, no haremos uso de las frecuencias porcentuales.
| Color | Frecuencia absoluta | Frecuencia acumulada | Frecuencia relativa | Frecuencia relativa acumulada |
| Negro | 4 | 4 | 0,20 | 0,20 |
| Azul | 5 | 9 | 0,25 | 0,45 |
| Amarillo | 5 | 14 | 0,25 | 0,70 |
| Rojo | 6 | 20 | 0,30 | 1 |
| Total | 20 | 1 |
Ejemplo 2:
En una tienda de autos, se registra la cantidad de autos Toyota vendidos en cada día del mes de Setiembre.
0; 1; 2; 1; 2; 0; 3; 2; 4; 0; 4; 2; 1; 0; 3; 0; 0; 3; 4; 2; 0; 1; 1; 3; 0; 1; 2; 1; 2; 3
Con los datos obtenidos, elaborar una tabla de frecuencias.
Solución:
En la primera columna, colocamos los valores de nuestra variable, en la segunda la frecuencia absoluta, luego la frecuencia acumulada, seguida por la frecuencia relativa, y finalmente la frecuencia relativa acumulada. Ahora vamos a agregar la columna de frecuencia porcentual, y frecuencia porcentual acumulada.
| Autos vendidos | Frecuencia absoluta | Frecuencia acumulada | Frecuencia relativa | Frec. relativa acumulada | Frecuencia porcentual | Frec. porcentual acumulada |
| 0 | 8 | 8 | 0,267 | 0,267 | 26,7% | 26,7% |
| 1 | 7 | 15 | 0,233 | 0,500 | 23,3% | 50,0% |
| 2 | 7 | 22 | 0,233 | 0,733 | 23,3% | 73,3% |
| 3 | 5 | 27 | 0,167 | 0,900 | 16,7% | 90,0% |
| 4 | 3 | 30 | 0,100 | 1 | 10,0% | 100% |
| Total | 30 | 1 | 100% |
TEMA: Medidas de dispersión
https://www.youtube.com/watch?v=BSxdG6XpCwc
Indica la dispersión entre los valores extremos de una variable. se calcula como la diferencia entre el mayor y el menor valor de la variable. Se denota como R.
Para datos ordenados se calcula como:
R = x(n) - x(1)
Donde: x(n): Es el mayor valor de la variable. x(n): Es el menor valor de la variable.
Es la media aritmética de los valores absolutos de las diferencias de cada dato respecto a la media.

Donde:
xi:valores de la variable.
n: número total de datos
La desviación estándar mide el grado de disersión de los datos con respecto a la media, se denota como s para una muestra o como σ para la población. Se define como la raiz cuadrada de la varianza según la expresión:
Obsérvese que el denominador es n - 1, a diferencia de la desviación media donde se divide entre n; también existe la formula de desviación típica donde el denominador es n pero se prefiere n-1.
Mientras menor sea la desviación estándar, los datos son más homogéneos, es decir existe menor dispersión, el incremento de los valores de la desviación estándar indica ina mayor variabilidad de los datos.
Es otro parámetro utilizado para medir la dispersión de los valores de una variable respecto a la media. Corresponde a la media aritmética de los cuadrados de las desviaciones respecto a la media. Su expresión matemática es:
![]()
donde Xi es el dato i-ésimo y ![]() es la media de los N datos.
es la media de los N datos.
Permite determinar la razón existente entre la desviación estándar (s) y la media. Se denota como CV. El coeficiente de variación permite decidir con mayor claridad sobre la dispersión de los datos.
También puede ser expresado en por ciento.








